Открытый патент Панды
Упрощенное описание патента 8.682.892 на ранжирование страниц, изображений и других ресурсов, предполагающего наказание за содержание низкого качества.
Три года спустя был представлен алгоритм Панды, который рассекретил десятки миллионов веб-сайтов (примерно 20% от 300 миллионов), поставил под сомнение бизнес веб-мастеров и обанкротил бесчисленное количество сайтов электронной торговли. Мы будем рады узнать, что знаменитый алгоритм, который должен судить о качестве веб-сайтов и «создавать здоровую экосистему» по словам Google, сводится к простому уравнению: M = IL/RQ !
Однако в исследовании патента 8.682.892 не приходится сомневаться, что метод позиционирования, эффект от которого полностью соответствует новой работе поисковой системы, начатой 24 февраля 2011 года...
- Это принесло пользу таким крупным сайтам, как Amazon, eBay, которые увидели рост своего трафика на 30%.
- Это коснулось в основном средних участков. Очень многие площадки электронной торговли закрыли свои двери. И
- выгодно сайтам брендов.
- Сайты затрагиваются целиком, а не только страницы, представляющие меньший интерес.
- Старые площадки пострадали больше, чем новые.
- Затронутые сайты практически никогда не восстанавливают аудиторию, даже если улучшают свой контент. Некоторые, однако, смогли восстановиться, удалив большую часть своих страниц.
- 12% сайтов пострадали от первой итерации и тем более от последующих .
- «Панда» требует огромных ресурсов, и в первую очередь она реализуется через независимую программу, которую запускают примерно каждый месяц. Теперь известно, что это для построения разделов групп ресурсов всех веб-сайтов.
- Это было представлено Google как способ понизить качество страниц. Именно такая цель поставлена в патенте.
Тогда Google посчитала этот метод заслуживающим патента и 28 сентября 2012 года подала спецификацию 8.682.892.
И вот в деталях этот метод...
Метод Панды
Процесс, используемый для изменения ранжирования в соответствии с фактором Панды, заключается в разделении индекса на группы ресурсов, которые считаются связанными между собой .
1) Определяются группы ресурсов
Весь веб-сайт разбит на группы ресурсов. Ресурсы - это страницы, изображения и другие документы, которые могут отображаться в результатах и находятся в индексе.
Ресурсы классифицируются в одну группу на основе их URL-адресов, и в группу входят все документы домена, субдомена, набора доменов или одного хостинга.
Google также может определить принадлежность к группе на основе общих элементов: та же презентация, та же таблица стилей... (Есть надежда, что он не ассимилирует в группе все сайты, которые используют Bootstrap!).
После определения группы (сайта или набора узлов) ей присваивается фактор Панды, который будет применен к каждой странице группы. Ниже будет показано, как рассчитывается этот фактор .
Для упрощения описания группа ресурсов будет обозначена как «сайт», а ресурс - как «страница», но ты считаешь, что это сложнее.
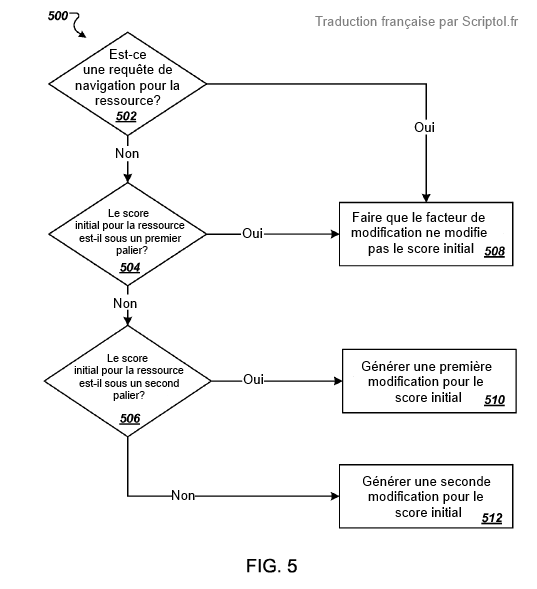
2) Определяется начальный балл страницы.
Когда система получает запрос от пользователя, она также получает список страниц с начальным баллом для каждой из них.
Этот ранее рассчитывался обычным алгоритмом по 200 критериям, в том числе PageRank.
Мы должны изменить его с помощью фактора Панды.
3) Мы идентифицируем группу...
Для каждой страницы программа определяет сайт, которому она принадлежит, на основе своего URL-адреса. Зная сайт, он восстанавливает связанный с ним фактор Панды.
4) Создается фактор, специфичный для страницы
Из Panda-фактора сайта вычисляется что-то более конкретное. Чтобы сделать это, сравниваем начальную оценку страницы с двумя последовательными уровнями.
Если первоначальный балл ниже первого уровня, фактор Панды отменяется.
Если первоначальный балл находится между первым уровнем и вторым уровнем выше, вычисляется конкретный фактор, который падает еще больше по мере увеличения начального показателя.
Если первоначальный балл находится выше этого второго уровня, фактор Панды в группе меняется формулой или алгоритмом, смягчающим его эффект.
5) Исключаются навигационные запросы
Когда пользователь делает запрос, направленный на поиск конкретного сайта или страницы, с указанием доменного имени или терминов, характерных для сайта или страницы, фактор Panda игнорируется, и страница будет классифицирована по своему первоначальному баллу.
6) Коэффициент изменения применяется к начальной оценке
Фактор Панды умножается на первоначальный балл, чтобы получить новый балл рейтинга, и последний будет использоваться для классификации ресурса в результатах.
Расчет коэффициента изменения
Вот как определяется фактор Панды для группы ресурсов, то есть связанного сайта или набора узлов.
1) Разбивает индекс на группы ресурсов
Это основано не только на URL, но и на других факторах, чтобы определить одного и того же владельца для набора ресурсов. Группа определяется как домен или поддомен, или набор доменов, принадлежащих одному лицу или организации.
2) Вычисляется количество независимых ссылок на страницы каждого сайта
Рассматриваются не только явные ссылки на сайт, но и ссылки на него, например, имя домена даже без тега ссылки. Ссылки независимы, если они не принадлежат к одной и той же группе ресурсов, поэтому, в зависимости от случая, они относятся к одному и тому же домену, субдомену или узлам одного и того же владельца или множеству узлов, связанных между собой.
Но можно также попытаться найти связь между исходной и целевой страницами. Та же таблица стилей, похожее содержимое, те же кадры. Можно рассчитать значение независимости и оценить, что это значение слишком мало, чтобы сделать вывод о независимости связи.
Система сохраняет только ссылку на каждой странице исходного сайта.
Он складывает все независимые связи.
3) Вычисляется количество запросов на страницы сайта
Вычисляется количество запросов ссылок на каждый узел/группу. Это запросы, сделанные разными пользователями, на страницы сайта. Пользователей идентифицируют по IP, cookie или любым другим способом.
Сложим все справочные запросы.
4) Определяется соотношение для получения фактора Панды
Facteur de modification = nombre de liens indépendants / nombre de requêtes de référence.
5) Нормализуют фактор Панды
В некоторых реализациях коэффициент изменения нормализуется.
Определяются интервалы количества справочных запросов и индекс разбивается на набор узлов/групп, принадлежащих к одному и тому же интервалу.
Коэффициент Панды каждого сайта нормализуется на основе других сайтов того же раздела, то есть из одного и того же интервала .
Для этого вычисляется среднее или медианное или другое такое измерение и используется формула:
Facteur de modification normalisé = facteur de modification - mesure / mesure.
Это новое значение сохраняется вместо начального коэффициента изменения.
Последующие изменения
Panda получила несколько изменений, некоторые из которых были обнародованы...
Ниши. Некоторые сайты предоставляют уникальную информацию в конкретных секторах и, тем не менее, имеют очень мало входящих ссылок. Мы пытались исправить Панду, чтобы спасти эти сайты.
Мэтт Каттс также заявил, что в новой итерации Панда учла тот факт, что когда пользователи, зарегистрированные на аккаунте Google, часто исключают сайт из страниц результатов, то тот получает пониженный балл.
20 мая 2014 года крупное обновление позволило многим небольшим сайтам выйти из песочницы Panda. Несмотря на то, что характер изменения алгоритма не разглашается, понятно, что Google в итоге учла, что небольшой сайт не может иметь столько обратных ссылок, сколько важный. Таким образом, он отвечает на критику, сформулированную в заключение.
Алгоритм и его эффекты
Содействуя возвратным ссылкам, Панда продвигает новые и актуальные страницы, шумиху. Накопленные старыми сайтами бэклинки со временем исчезают...
Панда не убирает глупости со страниц результатов, типа «если ты ищешь винт, который не ломается, покупай в более прочном». Но такой ответ сейчас дают крупные сайты общего профиля, которые занимают место контентных ферм. Новая тенденция?
SEO теряет большой интерес к Панде. Никакая работа над ссылками не может увеличить количество полностью независимых обратных связей. Они зависят от содержания. И активизм. Но знание поисковиков по-прежнему полезно для решения многих проблем вебмастера, таких как перенаправления, смена доменов, дубликаты, микродаты и т. Д.
При равном качестве, чем больше у сайта посетителей, тем больше шансов получить обратные ссылки. Соотношение объясняет, почему сайт не может восстановиться после того, как его оштрафовала Panda: как получить больше ссылок на возврат, когда аудитория значительно сократилась ?
Зная, что один сайт ежедневно принимает 10000 посетителей, а другой - 1000. Если каждый из них разместит страницу на одну и ту же тему с одними и теми же ключевыми словами и получит один и тот же первоначальный балл, то у первого будет в десять раз больше ссылок из-за количества посетителей и, следовательно, более выгодный фактор Панды.
Но как это говорит о более высоком качестве контента ?
Когда ответ на сложный вопрос не появляется на важном сайте, его становится сложнее найти. Популярность привилегирована.
В зависимости от используемого соотношения, если сайт представляет изображение, которое становится вирусным и получает миллион ссылок, все, что будет опубликовано на этом сайте, будет считаться качественным и получит лучший рейтинг. Качество сайтов по понятию Google оценивается по алгоритму низкого качества.
Обновление Май 2014: Во время новой итерации 20 мая, кажется, было учтено (через 3 года), что меньший сайт не может получить столько бэклинков даже с оригинальным и информативным контентом .
Автор: Денис Суро, 14 апреля 2014 года .
Другие изображения, сопровождающие патент:
- Схема поисковой системы. На котором реализован запатентованный метод.
- Шаги алгоритма Панды.
- Расчет коэффициента изменения.
- Нормализация коэффициента изменения.